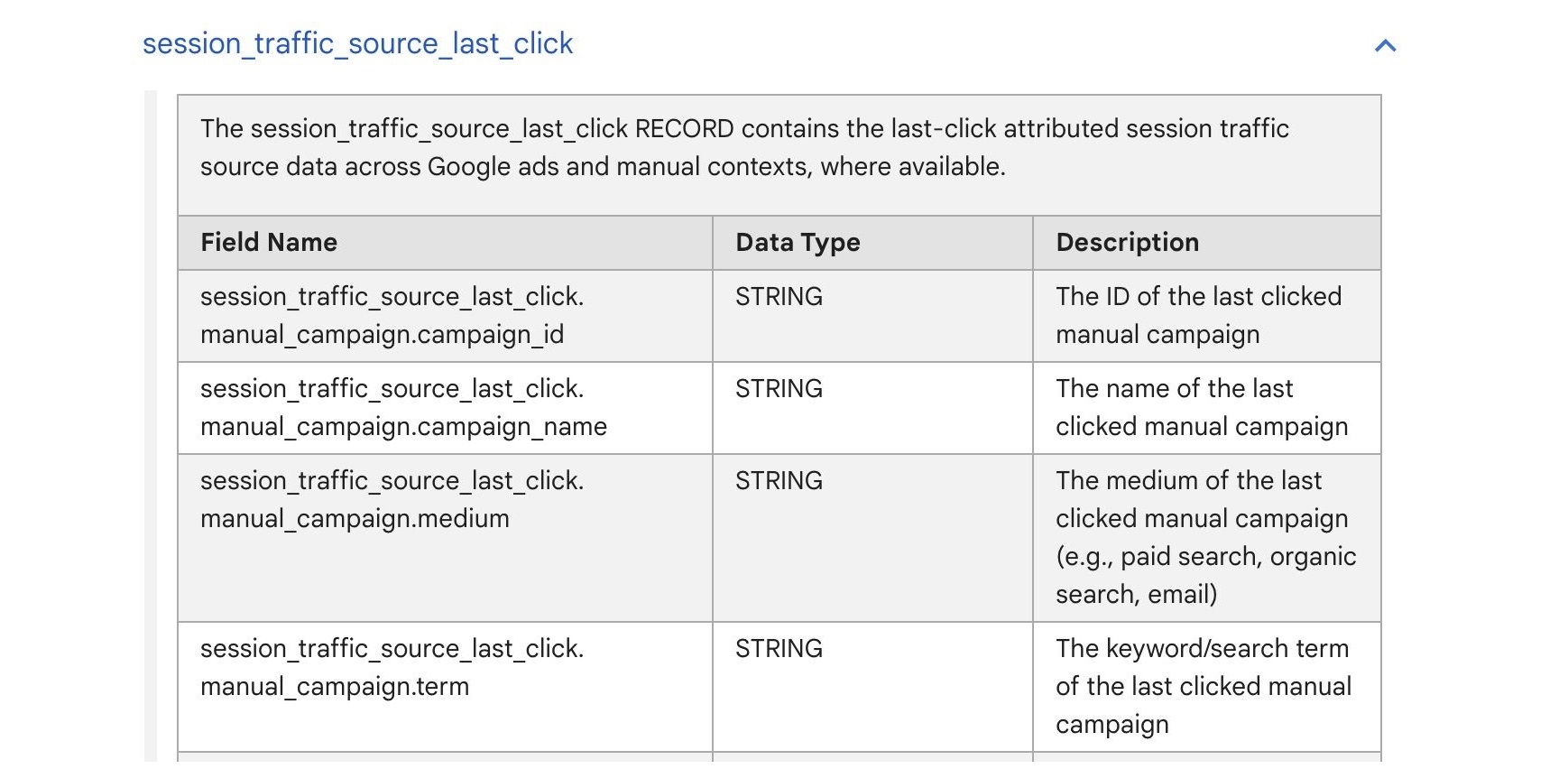

Calculating a rolling count distinct in BigQuery can be challenging, especially when working with time series data. If you’re trying to find how many unique users logged in over the past 30 or 365 days, analytic functions might seem like the obvious choice. However, they quickly run into limitations.
At first glance, it seems easy to use BigQuery’s analytic functions with a COUNT(DISTINCT) over a partitioned date range. Unfortunately, this doesn’t work because BigQuery doesn’t support COUNT(DISTINCT) in rolling aggregations, leading to errors like "Window ORDER BY is not allowed if DISTINCT is specified."
One workaround is to group user_id's into arrays by date, then count distinct users within each array. This works on small datasets but quickly becomes inefficient when dealing with larger datasets (e.g., 10,000 users). It can even lead to "Out of Memory" (OOM) errors.
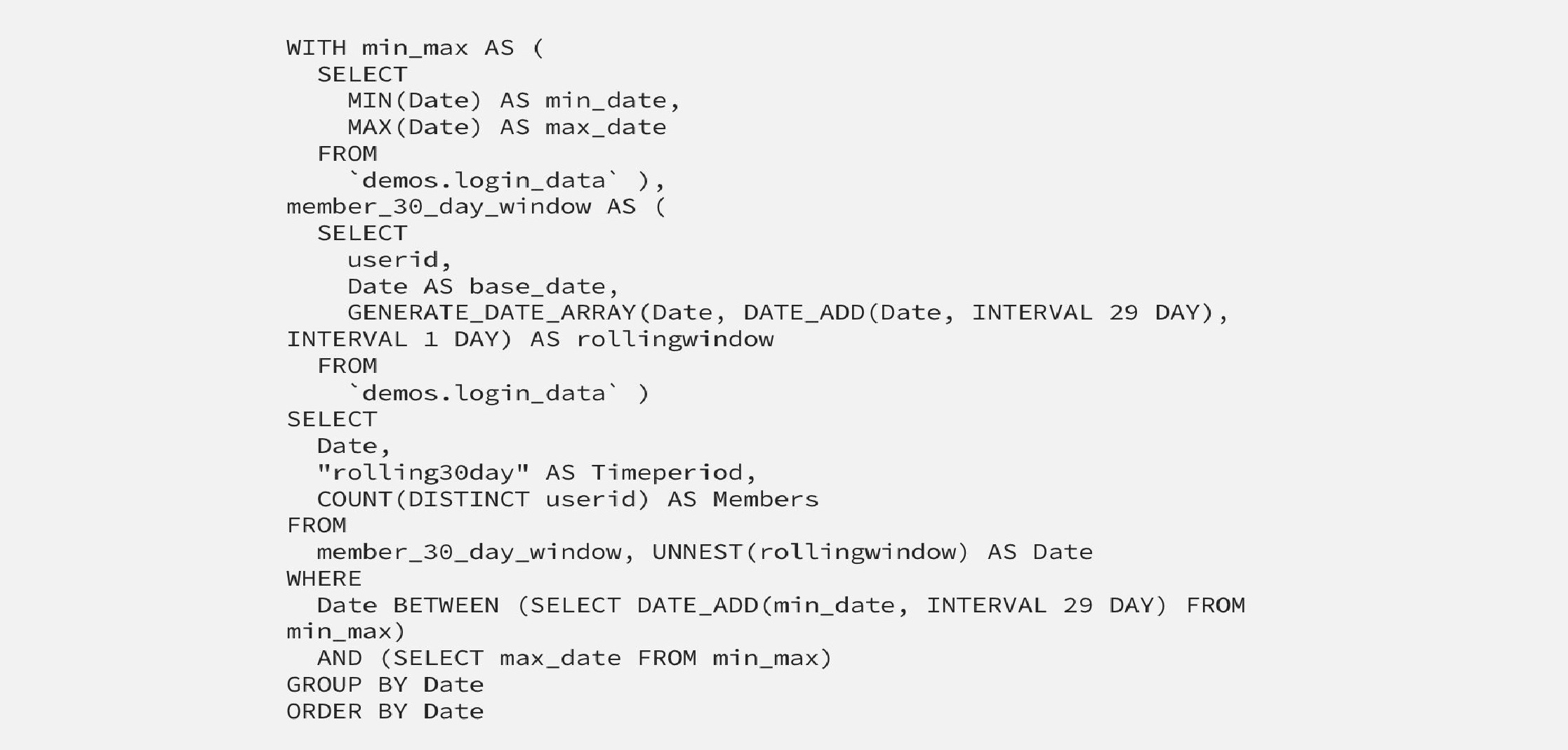
The better solution is to avoid analytic functions and restructure the data differently:
1. Generate a new column from the Date column, which contains an array of the next 30 days (for calculating monthly active users): GENERATE_DATE_ARRAY(Date, DATE_ADD(Date, INTERVAL 29 DAY), INTERVAL 1 DAY).
2. Unnest the generated dates array so you can perform a COUNT(DISTINCT user_id).
3. Adjust the date range to remove dates that don’t have enough history for a proper rolling window.
This solution, originally proposed by Huijie Wang turned out to be the fastest and most cost-effective method for calculating rolling metrics like Monthly Active Users (MAU) and Weekly Active Users (WAU).
If you work with GA4 to BigQuery exports, be sure to check out my SQL cheat sheet.
Want all my posts in one place? I put 350+ articles on GA4, BigQuery, attribution, and metrics into one searchable library.
Go here to explore it for FREE.